新地图艾兴瓦尔德
更新完音频小站上线体验了一把新地图。
艾兴瓦尔德,德国小镇,智械危机中莱因哈特所在的十字军死守的小镇。十字军在此一役中几乎全军覆没,但为后方大部队的集结争取了时间,人类从而获得了反攻的机会并最终赢得了胜利。(大概是这样的剧情吧)《最后的堡垒》短片里有一段回忆也和这场战役有关。莱因哈特在这地图上也有特殊相关台词。
体验了几把,包括使用自定义跑图,感觉是对进攻方非常不友好的地图。大概是随着游戏被越来越多的玩家深入理解掌握,各地图进攻方的优势和胜率越来越大,逼得暴雪通过地图加强防御方了。
但从全局看,这图怕是更难做到攻防平衡。
A 点路口
在所有的占点推车混合图里,这图是唯一一个 A 点只有一条直路可供大部分英雄通过的了,对于同类型的努巴尼,A 点有四条路线,任何一条路线都可以集体进攻。国王大道也有右侧二楼的集体路线。即使是好莱坞也有一个侧门,虽然对于鱼塘局作用不大但也偶有奇效,况且好莱坞大门处防守方掩体不足,很难死守大门,完全阻止进攻方突进英雄从左侧绕后。
但这个新图真的差不多准心瞄准桥头就行了。桥左破房子翻过去也只能骚扰,很可能在没有技能时直接面对对面两三个英雄,右侧只有法拉 D.VA 能飞,并且也要耗费完主力技能(飞行)才能通过。占点圈也比其它地图小,并暴露在三处高点下。
进攻方大部队我想不出什么其它策略,只能正面强冲。顶多就是利用温斯顿、法拉天使双飞、源氏、猎空之类的从桥上翻跃,勉强算是半个绕后。但温斯顿单重装强冲往往瞬死,如果想再加上查莉娅盾、禅雅塔谐,那么查莉娅和禅雅塔还是得从桥下经过,落单反而更容易死。对于水平相当的对战,很难想通过源氏、法拉等个人超水平发挥来牵制两名以上防守方英雄足够长的时间,让剩下 5 名队友获得足够长时间的人数优势从而压制并控制桥洞。
A – B (城门)运载路线
运车路线全程都很狭窄,并且左右优势高地众多。进攻方由于必须推车,并没有很好的分支路线选择,顶多就是源氏法拉略微脱离人群打开视野,而防守方却有多个选择,甚至可以集体绕后或居高临下强冲。尤其是 A B 点之间那段路,对进攻方简直是恶梦。前半段几十米路有三个弯曲,暴露在至少五六处不同高地的火力覆盖范围内,防守方登上城墙以后不用绕直接就可以突袭进攻方后方辅助位。同时路线狭窄,查莉娅大招、小美大招甚至温斯顿大招都可以分割整条道路。这前半段是少有的防守方可以在任何位置都可以主动寻求开团的地图版块了,比好莱坞 A B 段还强硬,至少好莱坞两个房顶只能占一个。
后半段则是奈何桥,这桥防守方重生路线比进攻方略短,交换人头会积累微弱的优势,同时左侧的城墙高点还能发挥作用,进攻方要上城墙需要从左边绕一大圈,而防守方只是顺路。进攻方需要尽量避免在桥上长时间作战,被迫作战也要尽量以攻城锤为掩体,否则全场最佳大概就会变成法拉的了。对鱼塘局而言,有大门遮挡视野,防守方重生英雄很难中途被截,必然可以赶到战场,而进攻方重生英雄则要面临整条路线上的任何可能位置的埋伏。
这段路线尽管非常短,差不多是所有地图中最短的一条,但同时也是最易守难攻的一段了。
B – 运载终点
这段防守方的优势没有前面的大了但依然存在,一是拐弯左侧小道利于防守方,二是依然狭窄的道路对于防守续命英雄(温斯顿、美、D.VA 等)也都是利好。但其实在我看来,这段路线对进攻方的最大压力已经不在于地形,而在于经过前两段路以后,捉襟见肘的剩余时间了。
总结
主路小,几个关键关卡点没有分路,繁多的支线和立体地形,使得防守方的优势极其巨大。由于鱼塘局和高端局在攻防配合上的天然差距,这图会成为鱼塘进攻方的恶梦,同时对于高端局而言,也因为存在过大的不确定性,导致 Banpick 中被选出的可能性较小。
源氏、法拉等立体机动性英雄和狂鼠等封路英雄优势较大,而猎空却受限明显,黑百合在 A 点桥门和 B 点奈何桥的争夺中可以当奇兵一用(狙掉两个,强冲一波)。
由于制作地图工程量巨大,后期也很难修改,所以猜测暴雪会在日后加快推车速度以平衡一下鱼塘进攻方的劣势,不会修改地图本身。但由于高端局和比赛是『一次团战胜利推一段』的模式,较短的路线和加快的车速又会变成进攻方的优势。就是说,这个地图放大了配合推进的重要性,导致鱼塘和比赛的攻防胜率更加割裂。不知道暴雪之后会怎么处理,会不会出现加快 AB 段车速减慢 BC 段车速的奇葩情况。拭目以待。
 编辑语音标签
编辑语音标签 根据标签筛选
根据标签筛选



 其实就是 Tasksel 整合安装器
其实就是 Tasksel 整合安装器
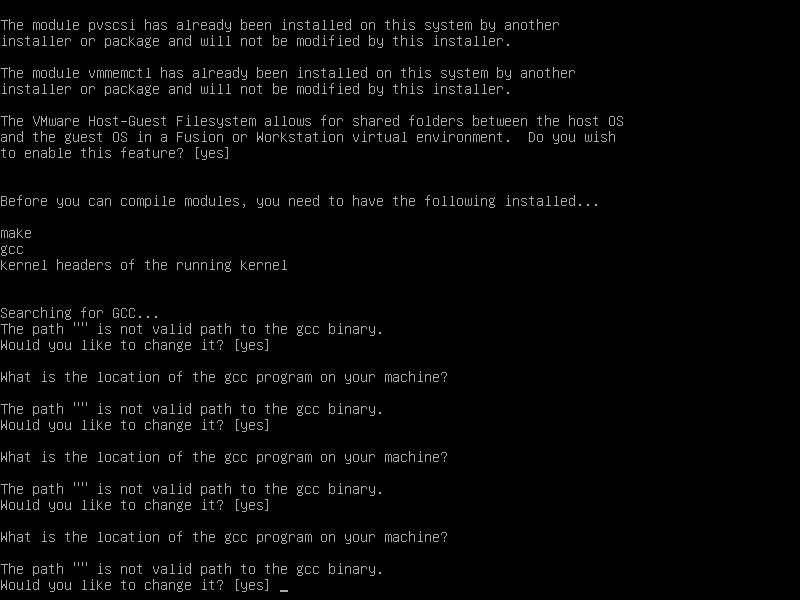 gcc 路径为空,无限循环无法往下
gcc 路径为空,无限循环无法往下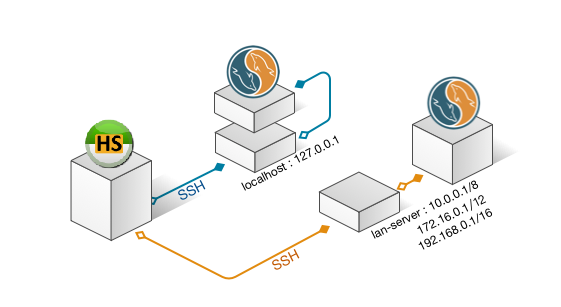
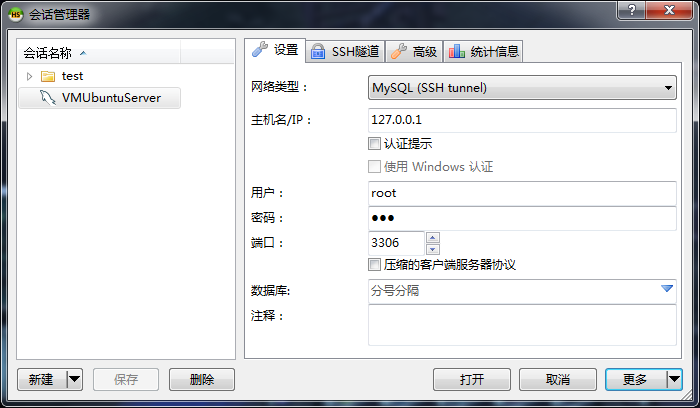 SSH 主机(不是本机)如何连接到数据库,很多中小网站的数据库只允许本地访问,则这里应当填写 127.0.0.1
SSH 主机(不是本机)如何连接到数据库,很多中小网站的数据库只允许本地访问,则这里应当填写 127.0.0.1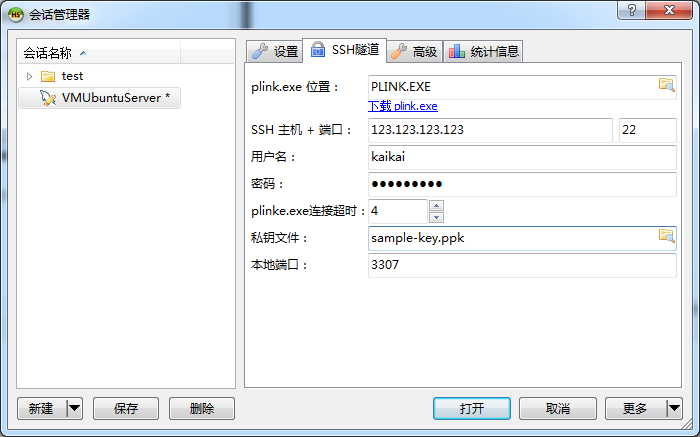 本机如何连接到 SSH 主机
本机如何连接到 SSH 主机 100 万亿元津巴布韦币
100 万亿元津巴布韦币